citeprocで日本語と英語の文献をそれぞれ違うスタイルで生成する
pandoc と citeproc を使って文献情報を生成しているのだが、日本語と英語の文献を引用する都合上、それぞれのスタイルで文献リストを作る必要がある。
しかし、デフォルトでは複数の言語ごとのスタイルで出力することには対応していないようなのでどうにかハックする必要があるようだった。
そこで、あまりきれいではないが、暫定的にどうにかしたので手順を書いておく。もっといい方法があればぜひ教えてほしい。
前提
今使っている状況を書いておく。
- 論文は Markdown で書いている
- 文献は Zotero で管理している
- Zotero から bib を出力している
- citeproc を使って、文献リストを生成している
- CSL ファイルは Visual CSL Editor で編集している
複数言語の難しさ
基本的には CSL をいじって、イメージどおりのスタイルでインラインの文献情報や文献リストが生成できるようにする。
問題となるのは、CSL で日本語と英語の文献をどのように識別するかである。
CSL では、いろんな項目を見て分岐する機能はあるが、その値ごとに分岐できない。
つまり、languageという項目は見られるが、languageがjaかenかで分岐できない。
だが、値が存在するかどうかはチェックできるので、日英を判定するための項目を専用で設けて、それを使う方針にした。
大まかな方針
まずは、bib に専用の項目を作る。
元々languageという項目は Zotero で管理している情報内に含まれているが、jaとenの両方が入っているのでそのまま使うことはできない状況だった。
なので、この情報をスクリプトで加工して、languageという項目を、日本語の文献にはjapanese、それ以外には空を入れるようにした。
あとは、CSL でlanguageがis presentかどうかで分岐するようにすればいい。
日本語か英語かで分岐ができるようになったら、あとはお望みのスタイルに頑張れば調整できるはず。
bib を加工する
元々は、次のような.bibファイルを使っていたが、これはスクリプトで加工がしづらい。
@article{rawls1963,
title = {The {{Sense}} of {{Justice}}},
author = {Rawls, John},
year = {1963},
journal = {The Philosophical Review},
volume = {72},
number = {3},
pages = {281--305},
publisher = {{[Duke University Press, Philosophical Review]}},
issn = {0031-8108},
doi = {10.2307/2183165},
}
そこで、Zotero でBetter CSL JSONで出力するようにした。
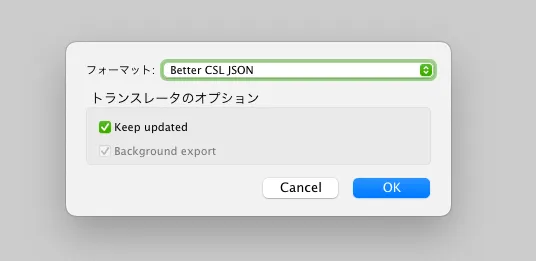
pandoc では.jsonでも問題なく読み込めるので、これを使うことにした1。
そして、JSON であれば、node で簡単に修正ができるので、languageの値を次のスクリプトでいい感じにする。
const path = require("path");
const fs = require("fs");
const mainBibPath = path.join(__dirname, "path-to-input-bib.json");
const mainCustomizedBibPath = path.join(__dirname, "../", "path-to-output-bib.json");
const mainBib = JSON.parse(fs.readFileSync(mainBibPath, "utf-8"));
const convertedMainBib = mainBib.map((entry) => {
const { title } = entry;
// 日本語を含むかチェック
if (title.match(/[^\x01-\x7E]/)) {
entry.language = "japanese";
} else {
entry.language = undefined;
}
return entry;
});
fs.writeFileSync(mainCustomizedBibPath, JSON.stringify(convertedMainBib));
CSL をいじる
あとは、languageの項目を使って、必要なところで分岐させる。
この編集ツールを使って基本的にやった。
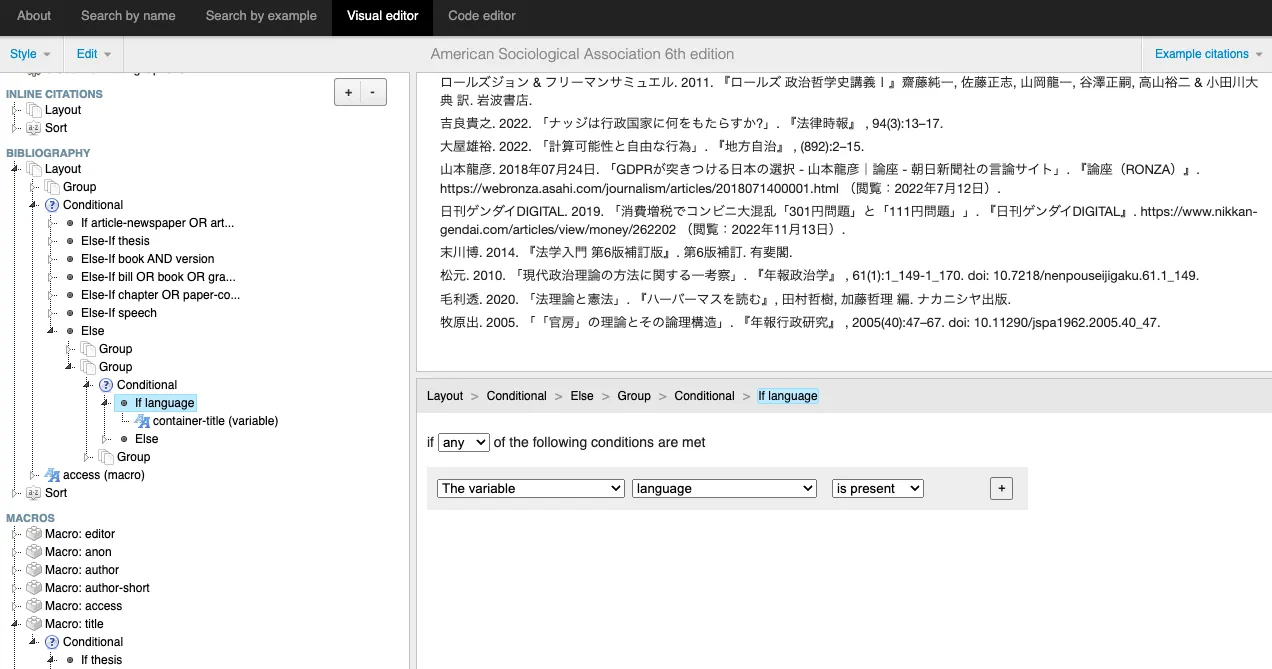
そうすれば、日本語と英語で分岐できるようになる(はず)。

(以上はスタイル生成時に使った適当な文献情報)
まとめ
最低限日英で出し分けることができた(はず)。
でも 3 言語以上になってくると、この方法では問題が出るのでその場しのぎに過ぎない。
どうしてももう少しいい感じに文献情報を扱うツールが世の中にないのであろうか。それとも各々が秘伝のタレをもっているのだろうか…。
Footnotes
-
ただし、Visual Studio Code のプラグインの
Pandoc Citerは JSON だと認識しないのか、pandoc にセットするもの以外は.bibを引き続き使っている。 ↩